Performance reviews, written from evidence, not memory.
Arbor connects to your engineering tools, pulls real signals across the review period, and uses AI to produce a structured evidence brief for every engineer. You make the call.
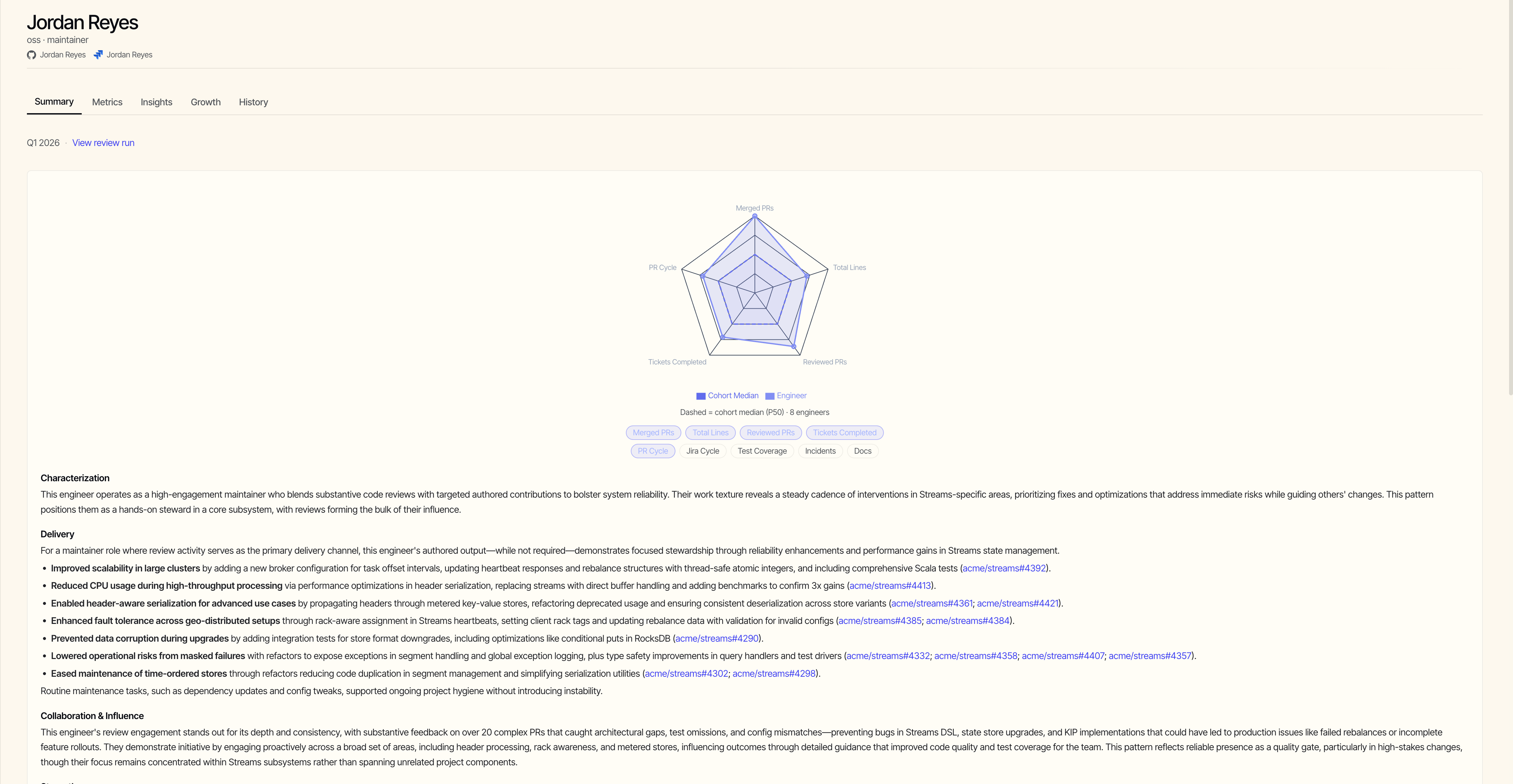
One brief per engineer, many lenses.
Every brief is the same shape: a calibrated summary, the underlying metrics, the trends behind them, and the trajectory across periods.
“I spend weeks turning scattered feedback into reviews that are fair, specific, and defensible.”
Recency bias decides outcomes.
The last six weeks dominate a six-month review. Steady contributors get under-credited; recent firefighters get over-credited.
The signals are already in your tools.
GitHub has every PR, every review, every comment. Jira has the tickets, the cycle times, the delivery patterns. The story is there. Nobody has time to read it.
Calibration starts from a blank page.
Managers walk into committees with a few anecdotes and a vibe. Calibration drifts toward whoever speaks loudest, not whoever has the strongest evidence.
Engineers feel it too. A different version of the same problem.
Managers can't see the work clearly. Engineers can't see the decision at all. We asked people across consulting, banking, big tech, and startups how they're actually reviewed. Many different processes, the same underlying disease.
“The visible process is one thing. The real process is calibration, and we never see it.”
“Manager's opinion only. Performance calls are just formality.”
“You're assigned a coach from another team who fights your case at review. How good they are matters more than the work.”
“Structured on paper. Manager's opinion in practice.”
“Whoever you ask for feedback matters more than what you actually did.”
“GRAD takes me a week to fill, just for me to be wondering who sees what.”
Quotes from individual contacts describing their employer's process. Lightly edited for clarity. Not affiliated with or endorsed by any company named.
Three steps. No setup ceremony.
Arbor is hosted. Connect once during onboarding, then kick off a review run whenever the cycle comes around.
Connect your engineering sources.
GitHub, Jira, and Confluence today, with more on the way. Personal access tokens or OAuth, whichever your security team prefers. Read-only access only, credentials encrypted at rest.
Select engineers and review period.
Pick a cohort: a team, a sub-team, an org. Pick a date range. Arbor handles the cohort calibration math.
Read the evidence briefs.
One brief per engineer: deterministic metrics, an AI-powered narrative grounded in citations, cohort-relative context. Read in-app or export the structured data.
A brief, not a verdict.
Arbor's output is a structured document the manager and calibration committee read together. Every section is grounded in evidence the team can re-open.
Metrics you can verify.
PR throughput, code review depth, cycle time, ticket health. Every number is computed from raw events you can audit. No black-box scoring.
AI-powered synthesis, fully cited.
Arbor turns hundreds of events into a paragraph that reads patterns, not platitudes. Every claim links back to the PR, comment, or ticket it came from.
Cohort-relative, not absolute.
Engineers are compared within their team, over the same period, doing comparable work. The cohort is the calibration; nothing gets stacked against an external benchmark.
Evidence brief, not a rating.
Arbor produces the structured artifact your calibration committee anchors on. The brief never outputs a rank or recommendation; that judgment stays human.
Built for teams that read the security review.
Arbor is hosted to the same constraints your platform team would impose. Read-only access, encrypted credentials, no model training on your data.
- Read-only scopes. Arbor cannot write to your repos or your tracker.
- Integration tokens are encrypted at rest with AES-GCM and only decrypted in-memory at the moment of an API call.
- Your data is never used to train models, yours or anyone else's. We use the providers' no-training API tier.
- Delete a review cycle and the underlying events cascade out with it. Sub-processor list and DPA available on request.
github: "repo:read" "pull_request:read"
jira: "read:issue" "read:project"
confluence: "read:confluence-content.all"
"read:confluence-space.summary"
# tokens at rest
storage: "aes-256-gcm"
in-memory: "per-call only"
# your data, your kill switch
retention: "on-cycle-delete"
training: "never"
Worth asking.
- Will my engineers feel surveilled by this?
- Arbor reads what's already public to your team: the same PRs, comments, and tickets a manager would scroll through manually before review season. There's no new instrumentation, no time tracking, no IDE telemetry, no presence detection.
- What about work that doesn’t show up in a PR or ticket?
- For docs (design docs, RFCs, ADRs, postmortems, runbooks), connect Confluence and Arbor pulls page activity automatically into the brief alongside code and tickets. For work that's truly off-tool (mentoring, hiring, on-call rotations), that's exactly why Arbor ships an evidence brief instead of a rating: you and the engineer add the rest before the calibration committee sees it.
- Won’t this just push engineers to game the metrics, more PRs, more lines?
- Three guards. The metrics are cohort-relative, so the arms race is bounded by what's actually shippable on this team. The narrative grounds claims in linked evidence, so a wall of rubber-stamp PRs reads as suspicious instead of impressive. And the brief itself never outputs a rank, score, or rating. Engineers don't have a number to optimize toward.
- Why trust AI with something this consequential?
- Every metric is auditable from raw events; every narrative claim links back to the PR, comment, or ticket it came from. If you can't re-open the source, the claim doesn't ship. You're not trusting the AI, you're auditing it.
- What if my team uses a different tracker?
- GitHub, Jira, and Confluence are connected today. Other code platforms and trackers are on the roadmap; if a specific tool blocks a real rollout for your team, that's exactly the kind of feedback the beta is for.
- What does it cost?
- Free during the beta. Paid pricing isn't finalized; per-seat-per-month is the likely model, and we'll tell you before any charge ever happens.